Data Migration
Data Migration
Notes from an RxWorks conversion
This is the beginning of a set of notes from my experiences in doing a conversion from RxWorks to OpenVPMS. This is not intended to be a polished document, but rather a set of notes on things I have come across. I will start this as one page, but as time goes on, I expect it will be restructured into a more accessible and logical form.
First some background: I know a lot about RxWorks and am familar with traditional relations databases, but this is the first time I have played with an entity-relationship database. The system I am converting runs 24/7 and hence I need a conversion process which is either fast enough to be done in say 3 hours, or can be pre-converted and then use catch-up/synchronise processing.
Dataload or Kettle plugin?
In case you didn't realise there are two ways of loading data into the OpenVPMS database, the dataload utility (which processes XML formatted data), or the OpenVPMS Loader plugin for Kettle.
The dataload utility has its place, and I use it to load a practice-tailored setup file that contains all the basic data including lookups, postcodes, etc etc.
However dataload does not have the performance required to load a large dataset. For this you need the Kettle plugin. (In my enviroment, Kettle can load 14000 customer records in 2 minutes, dataload needs an hour.)
Data conditioning
OpenVPMS provides very tight data validation through the use of lookup tables. RxWorks is far looser, and although it has lists for various items, it is not mandatory that the data entered matches whats in the lists. This means that any conversion from RxWorks needs to do a reasonable amount of data cleanup work. Fortunately Kettle is a good fast powerful tool for doing this. (The 2 minutes for 14000 customer records includes all the processing to correct the suburb names [found in either the RxWorks ADDRESS3 or ADDRESS2 slots], the titles, the account types, etc etc.)
SQL snippets
Because of the entity-relationship design, SQL queries are not as simple as with a traditional database. Put another way, it's not obvious how you have the write the query. Hence this collection of snippets.
SQL to show lookups
select lookup_id, name, code from lookups where arch_short_name = "lookup.suburb";
select lookup_id, name, code, arch_short_name from lookups where arch_short_name like "lookup.%";
Differences
Below are a number of differences that may need to be considered during conversion.
Appointment duration: RxWorks uses a start-time, duration setup; OPV uses start-time, end-time. Hence in general one calculates the end-time by adding the duration to the start-time. However, RxWorks will not let the appointment cross the midnight boundary, but OPV will. Hence to mimic RxWorks, you need to terminate any appointment that ends in the next day at midnight.
Negative invoices: RxWorks allows the total invoice amount to be negative, OPV does not. Hence, its tempting to simply convert these negative invoices into credits. However, if you need to link clinical event line items to invoices, then you cannot do this if the invoice containing the item has become a credit. The solution is to split the RxWorks negative invoice into a credit holding the negative items (which will normally be a discount line item) and an invoice holding the other items.
Standard labels: RxWorks has a concept of standard labels, OPV does not. Hence your product conversion code needs to generate specific label text for those products which use a standard label.
No temperature: RxWorks has fields for the patient temperature and weight; OPV has only weight. So unless you want to invent a temperature archetype and the support for it, you need to record the RxWorks temperatures in the Visit Notes field. You also need to educate the staff to record the temperature in the Visit notes.
Notes overflow: RxWorks uses a memo field (ie a huge text field) to hold visit notes; OPV provides 5000 characters. Hence your conversion code needs to be able to split long RxWorks visit notes in multiple OPV visit notes.
Summary/Reason: Rxworks also uses memo fields for other things, notably the visit summary; OPV's visit Reason field is 50 characters long. My solution was to put the first 50 characters in the Reason field, and if some were lost, to put the whole summary in the first line of the visit notes prefixed by "Summary:".
Other overflows: In the case of other overflows (such as the RxWorks Transaction Text going in the OPV Invoice Notes), I just discarded the excess - on the basis that although it is critical to keep the all of the medical history, the financial stuff is less important and can afford to lose text from the end of the invoice notes.
Discard old data: It is quite reasonable to discard some old information. In my case we discarded all counter sales over two years old, all quotes/estimates over 12 months old, all appoinment data over two years old, and all data pertaining to clients and patients whose records had been deleted. (RxWorks does not have full referential integrity and hence in some tables there will be records containing patients and/or clients who have been deleted.)
Database size: In these days of terabyte disks, one really does not have to worry about space occupied by the database. However the OPV database is much larger that the RxWorks database. Firstly the OPV database structure requires more space (I suspect about 50% more) for everything except the attachments. However, since in OPV, the attachments live inside the database, this adds hugely to the size. Moreover, most of the attachements are incompressible jpeg files.
This leads us to the offsite backup problem. Currently a zipped copy of the RxWorks database is FTP'ed offsite each night (around 150MB worth). The 5GB of attachments are copied to a removable disk once a week and this is held offsite.
With 5GB of attachments inside the OPV database, the nightly FTP is not going to work, and I do not currently have a solution to this problem. [Although the site is in Hong Kong where it is common to gigabit bandwidth available, in our our building, the uplink only runs at some 150Kbps.]
Conversion strategy
As I indicated at the beginning I need a conversion strategy that will work with a 24/7 business environment. I now know that we should be able to convert the system with about a 3 hour data-entry lockout. Hence the plan is as follows:
- shut down RxWorks and make a copy of the database
- restart RxWorks telling the night staff that they can use it to look up patient records, but that if they do any data entry, this will be lost
- convert everything except the >2year old visit and financial data (takes under 3 hrs)
- bring OPV up and tell the staff that they can do anything except look at >2year old records, and all attachments
- initiate the conversion of the >2year old data (takes about 2 hours)
- start genbalance running (takes about 45 minutes), and docload running (takes ???)
Note that implicit in the above is the fact that one can use OPV while the various load utilities (ie Kettle, genbalance, and docload) are running.
That's it for the moment. I may add more later and I will come back and fill in the ???? bits.
OpenVPMS Loader plugin for Pentaho Kettle
This documentation was generated as a result of using OpenVPMS 1.5 and Kettle 3.2
The OpenVPMS Loader Kettle plugin allows mass data to be loaded into the OpenVPMS database.
Since OpenVPMS uses an entity-relationship architecture, rather that the traditional relational database design, one needs a tool that understands the archetypes used by the system. Also, because one does not have the table record keys present in a relational database, there is the potentional problem that having say loaded customer Fred into the system, one cannot at a later time, load in Fred's pets - because Fred's identity number is not known (because it was generated internally by the loader). The Loader plugin provides for this by allowing you to specify an ID field that can be used at a later time to refer to the record previously loaded. Thus Fred's customer record can be loaded with say ID 'C004236' (with 004236 being his client number in some other database), and this ID can be used later when loading Fred's pets. This 'external-key to internal-id' data is recorded in the etl_log file in the database.
The Loader also automatically generates lookup data. Say that the customer archetype defines a field 'title' where the contents must be present in the title lookup table, then without auto lookup generation, you would have to first check the data set to be loaded to see what values are used for the titles (eg Mr, Ms, Dr, Professor, Mde, Doctor) and then create the title lookup table with these entries. With auto lookup generation, this is not necessary and the Loader will create the necessary entries for you. However, you do have the problem that if the incoming data quality is poor (with titles like Mr, MR, Mr. and M R) then you will end up with all these in the lookup table - and you will have to use the Replace facility to clean things up. Hence pre-cleaning of your data is recommended (and Kettle is a very good tool for doing this).
The Kettle Transform step definition window contains the following: (obvious things like the OK button are omitted)
ID Field Name: the name of the field which you want to use as your 'external-key'. This field can be left empty, but you will not be able to later refer to the records being loaded.
Batch Size: this set the number of records loaded before a commit is done. Increasing the number increases the performance at the cost of losing data if a abort occurs. So setting it to say 99999999 will ensure that only one commit is done at the end of the run, but if anything goes wrong nothing will be loaded because all records added will be rolled back out as a result of the transaction failure.
Actually - although the above is logical, its not true. Benchmarking has shown that 50 to 200 is a reasonable optimum for performance.
Generate Lookups: The checkbox is left from previous versions - lookup generation is now always enabled. See OVPMS-1240.
Skip Processed: This checkbox tells the loader what to do about pre-existing records with the same 'external-key'. ie if you have loaded Fred's record in a previous run, what happens when you try to load it again.
If checked, a row that has been previously processed successfully will be skipped.
If not checked, all rows will be reprocessed. Care needs to be taken as this can result in duplicate objects being created.
The following can be set for each field:
Field Name: the name of the field in the step's input record
Map To: The entry here identifies the field to be loaded.
For simple fields its the archetype name and field name, for example <party.customerperson>firstName.
For collections it will have a format like <party.customerperson>contacts[0]<contact.location>address where the index [0] defines this as the first contact.
For cases where you wish to refer to a specific identifier it will have a format like $CLID<party.customerperson>contacts[1]<contact.phoneNumber>telephoneNumber - here CLID is the name of the input field that contains the 'external key' of the customer record loaded earlier for which you wish to set the 2nd contact to be the specified phone number.
Note that the indexes are not absolute indexes - ie its not as though the collection has a set of numbered slots. The indexes serve only to separate the entries for the loader. Hence if we use the second form above (where we are specifying a contact for the customer referenced by $CLID) then the loader will just add this contact to to the customer - and if the customer had 6 contacts already, this will be the 7th, not the second as the [1] appears to indicate. Put another way, the ONLY time you need to use other than [0] as the index is when you happen to be loading multiple members of the collection in the one loader step such as in the example below.

Exclude null: This controls what happens when the incoming field has a null value.
If this is set to N, then a null input will be set on the output field, replacing any default value.
If this is set to Y, then a null input won't be set on the output field, and the default value will be set. If there is no default defined for the field, it will be set to null.
Hence this setting determines whether or not the default value is set for fields whose incoming value is null.
Note that in the supplier example above, the Y's set for the contacts mean that if a field (eg oFax) is null then no fax contact will be created. This means that one does not have to worry about having separate loader steps to cater for cases where some of the data is missing. You just code for thr full data set as above, and rely on Exclude null=Y to omit the fields for which you have no data.
For these cases one uses code like the following in a preceding Javascript step:
var oFax = ""; // init fax number to empty/null
if (SupplierFax != undefined) { //if fax set in data record
oFax = SupplierFax; //set it
}
Value: If you leave this blank, then the data from the incoming field is put into the 'map to' field. However, you can enter expressions here. These will normally operate on the incoming field data in some way as to produce a different value that is put into the 'map to' field. The incoming field data is referred to using '$value'. There are two common formats used here when we are processing fields that have lookup constraints:
a) the <archetype>$value form of the mapping is used when the value refers to an object identifier (see examples below), and implies that the item being referred to must have been previously loaded by the loader.
b) the <archetype>nodename=$value form is used when the value refers to something to be looked up. NOTE that at the current time (1.5.1) the lookup will not be successful if the value you are trying to match contains spaces. See OVPMS-1258
Exclude default objects: As of OpenVPMS 1.5, the "Exclude default objects" column is ignored - you can set it to Y or N. See OVPMS-1239 for details.
Value Examples:
Mapping using nodename= (here we are loading a customer and as part of this setting the account type)
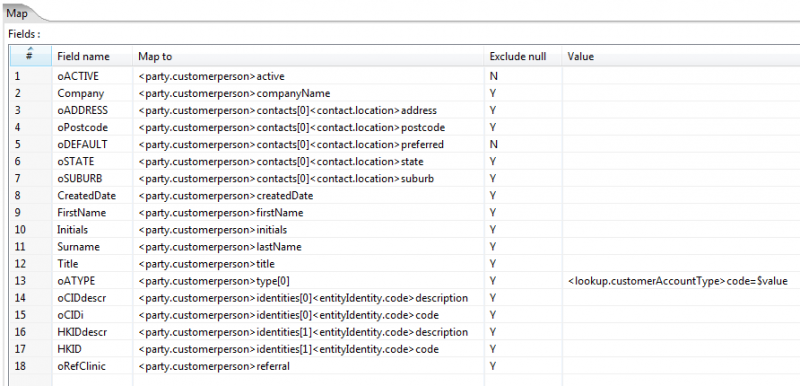
Mapping using values: (here we are connecting previously loaded customers to previously loaded patients)

Error messages:
The Loader plugin is not very good at error checking. a) Kettle's 'Verify this Transformation' checker will not always reveal errors in your entries; b) when an error occurs during the run, the error message is likely to contain little useful data. However, you may find the following helpful.
Message: "Row doesnt contain value: {0}" errors on every row
Meaning: "You twit, you have specified a field name here that is not one of the input fields - check your spelling and capitalisation - also use Get Fields to grab the names of the incoming fields".
Message: "Unexpected error null:" as follows (where 'OpenVPMS Loader.0' is the step name:
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : Unexpected error: null
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : java.lang.NullPointerException
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.load.RowMapper.mapValue(RowMapper.java:192)
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.load.RowMapper.map(RowMapper.java:161)
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.load.Loader.load(Loader.java:115)
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.kettle.LoaderAdapter.load(LoaderAdapter.java:110)
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.kettle.LoaderPlugin.processRow(LoaderPlugin.java:118)
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.kettle.LoaderPlugin.run(LoaderPlugin.java:187)
Meaning: you have mis-spelled one of the Map To entries
Message: "Failed to retrieve object" as follows (where nnn is the row id and XXX is the value you are tyring to lookup)
OpenVPMS Loader.0 - Failed to process row nnn: Failed to retrieve object: <lookup.customerAccountType>XXX
Meaning: either you have used the 'object identifier' form rather than the 'code' form (see Value: above) or the object you are referencing really does not exist. See also etl_log below.
Boolean fields
Kettle understands boolean fields. OpenVPMS has boolean fields. However, fields being processed by the Loader should not be in boolean format but rather integer or numeric/precision 0. If you try to load a field like <party.customerperson>active with field typed as boolean, then it will always be set to False. You have to use a Select Fields (or other) step to change the meta data to Integer. Then the field will get loaded correctly. 1 = true, 0 false.
Tricks of the trade
dataload integration If you load data with the dataload utility, then although it uses ID's to link the data being loaded, these IDs are not added to the etl_log file and thus cannot be used by the Kettle loader. However, there is no reason why you cannot inject records into the etl_log file to allow you to link to the records that you loaded using dataload. The attached etl_users.ktr illustrates this. It grabs the user information loaded earlier by dataload and creates the necessary etl_log entries so that when using Kettle to load say visit data, it is easy to reference the associated users and clinicians.
separate steps for linking Because of OPV's entity-relationship structure, is it very common to need to link things together. One of the most basic is the need to link patients to customers. While you might think - load the customers first, then as I load each patient, I will link it to the appropriate customer. This doesn't work - as you attempt to create the link between the customer and patient, although the customer connection will appear to work, the patient end will not. What you need to do is use one transform to load the customers, then one to load the patients and finally a third to build the links between them. Below is an example of the mapping in the Loader transform step used to do this. Note that the ID Field Name for this step is oCRN. oCRN can contain anything that is different on each row - I used the row number of the record from the RxWorks Patient-Owner file I was loading. oCID is the ID of the customer loaded earlier and oPID the patient ID.

SQL editing Kettle uses SQL to pull data from the database you are converting. However, it has very very rudimentary facilities to let you develop the required SQL queries. In my case (converting from RxWork's Access database), I found it far easier to build the query in Access, then display the SQL equivalent and then copy and paste it into the Kettle Table Input step. Because of the join limitations of Access, in some cases you will have to build a prior query in Access (so that the SQL you use ends up using both the RxWorks tables and the prior query you created).
Debug info I found it very useful to have a Text File Output step at the end of the transform which dumped every field from every record/row into a CSV file. When there were errors, this enabled me to look both at the rows in which there were errors, but also at the data in the rows which did not cause an error.
Abort step I also found it useful to have an Abort step as the very last step. During development, you can limit the number of rows processed. When all is working, you just disable the link to the Abort step and all data will be processed. (And because of the 'Skipped Processed Records=Y' setting, the 50 rows at the beginning that loaded with no error will be skipped automatically.)
etl_log An understanding of the etl_log file structure is useful. [More correctly its a table - 'file' betrays my age.] If you use the MySQL Workbench or equivalent you will find that it has three fields of interest (as well as others):
row_id - this contains the value from the field set as 'ID Field Name'
archetype - this contains the archetype being loaded (eg entityRelationship.patientOwner in the example above)
loader - contains the name of the Loader step. This is useful in figuring out which transform/step resulted in this record (sorry 'row').
Hence a useful query is something like 'select * from etl_log where archetype="entity.investigationType" order by row_id;'
Note that since the lookups are done on the basis of archetype/row_id there absolutely no problem in using the same ID's for two different archetypes. There is a major problem if you use the same ID more than once for the one archetype. [There will not be any problem as the data is loaded, but if you ever need to reference it, you will get 'refers to multiple ...' errors.]
Product varieties OPV divides products into three varieties, medication, merchandise, and services, each with its own archetype. This means that when loading product data, you need to use three different OPV Loader steps, and steer the processing to use the appropriate one (see below). Hence your processing needs to have some method of deciding on the variety of the product. Bear in mind that only medications can have labels, hence if there is some product that you think of as merchandise, you will need to class this as medication if you need to be able to print a label for it. (The example I found was a shampoo, which required a 'for external use only' label.)
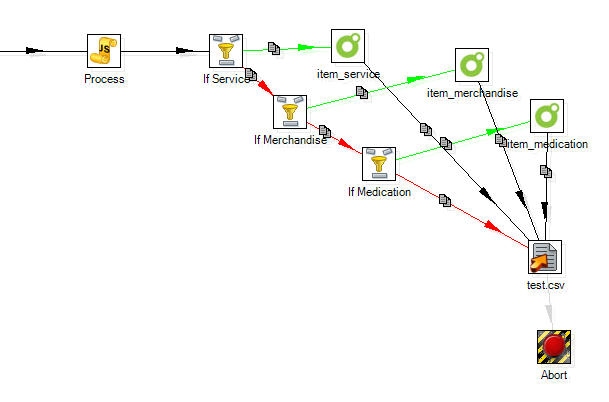
Need to Split Processing In some cases where you need to process medications, merchandise, and services it may be necessary to split the transform. That is, although you might think that its possible to use a transform with the above design with three separate loader steps, if you do this, you will get problems with Kettle running out of heap space. The solution is to clone the transform into 3, with each just processing one product variety. The problem seems to occur if the loader needs to update multiple records. For example the mapping given below (in which I am setting the product type for products loaded by an earlier transform) caused heap overflows if I used the above '3 loader steps in one transform' design, but ran happily when I split it into three transforms, one for each of service, merchandise and medications.

Reading the archetype As you are developing transforms you will want to refer to the archetypes. Don't using the Export facility on the Administration|Archetypes screen - it generates a very complete but overly complex adl file. If you do want to look at a file, grab a copy of the adl file from the <OPV-HOME>\update\archetypes\org\openvpms\archetype folders. Alternatively, look at the archetype via the Administration|Archetypes screen. Note however, that if you use View, you will not be able to see the full archetype. Specifically, if the archetype has a node that links to multiple archetypes (eg participation.product's entity node), then if you use View, you will only be shown one. To see all four you need to Edit the archetype.
More Kettle tips and tricks
This note serves to document things I have learnt using Kettle (3.2).
What Java? Kettle does not appear to function correctly with a 64-bit JVM. It does happily run with Java 8. If you do want to run Kettle (with a 32-bit JVM) and Tomcat (with a 64-bit JVM) on the same system, this is perfectly possible. My experience is on a windows system so I configured Tomcat using C:\Program Files\Apache Software Foundation\Tomcat 7.0\bin\Tomcat7w.exe to explicitly tell it where to get its JVM (in my case C:\Program Files\Java\jre1.8.0_45\bin\server\jvm.dll) and I set the path environment variable to have C:\Program Files (x86)\Java\jre1.8.0_45\bin at the beginning.
Installation To expand on the recipe given elsewhere:
Download and unzip Kettle. From version 1.4 we are compatible with version 3 of the PDI so you can download version 3.2 - BUT not yet (at version 1.6) compatible with version 4 of the PDI.
Unzip the OpenVPMSLoader.zip file found in the import/plugin folder in the openvpms distribution. This should be unzipped into plugins/steps folder in Kettle.
NOTE: Kettle 3.2 ships with version 2.0.6 of the Spring framework, whereas the OpenVPMS Loader plugin requires Spring 3.x. Hence you need to:
1. backup your Kettle installation directory
2. remove libext/spring/spring-core.jar
3. copy the OpenVPMS jars to libext/spring:
cp plugins/steps/OpenVPMSLoader/*.jar libext/spring/
4. Start Kettle
Failure to do the above will result in a "No application context specified" error when the OpenVPMS Loader plugin starts.
Kettle is a really neat powerful tool. You may find the following will save you some time.
Log size The internal log is not of infinite size. If something goes wrong and you have an error on every row, the earlier records will be discarded. Also after an overflow situation like this, Kettle seems to be unable to fully clear the log. That is, you can clear it, and it appears to empty, but when you start a new transform/job the old stuff re-appears. To fully clear the log after an overflow, stop and restart Kettle.
External log You can specify the log file for a job or transform. If you specify it for a job, then the settings apply to all the transforms in the job (unless you provide log settings for them). Note that the records are batched out into the log - the internal log runs ahead of the external one, and in the event of a crash (most commonly a java heap overflow), you will not get all records in the external log.
Minimum logging = no errors If you set the logging level to Minimum, then if your transform has errors, these will not show in the log.
Can detach and park If you have a job that consists of a number of jobs and/or transforms done in sequence, you may wish to re-run the transform omitting some of the transforms/jobs. The easiest way to do this is to delete the hop at each end of the string you don't to run, then move this out of the way, and rejoin things so as to omit the transform/jobs you don't want to run. See below.

Always turn off Lazy Conversion Some of the input steps have a 'Lazy Conversion' checkbox. Do not tick it - using this leads to peculiar error messages.
Trim memo fields Some databases support a long text field called 'memo'. If you are processing this data, and you want to log it via the Text File Output step, make sure that you trim back its lenght. Left unaltered the field lenght is over a million characters and this will cause a heap overflow.
No registry start It is possible to have Kettle crash leaving its repository containing a screwed up transform. This may lead to Kettle crashing on start. The fix is to tick the 'No Repository' box on the startup screen. Then you can can connect to the repository once Kettle has started.
Performance Herewith tips to get the maximum performance out of Kettle:
- Give MySQL lots of buffer space (I run innodb_buffer_pool_size=3G).
- If possible put the database on an SSD - perhaps not wise for production, but for the conversion phase, the faster the disk, the better.
- Where possible run transforms/jobs in parallel. Since the basic pattern of work is 'compute in Kettle, write to MySQL', it turn out that running two jobs in parallel has little effect on the run-time of each. Three or four is possible given suitable hardware. Running multiple jobs is just a matter of creating a job containing multiple sub-jobs - like the picture below. Right-click on the Start element and select "Launch next entries in parallel". Note that the complete job does not finnish until all the sub-jobs have finished. You will need to think about what things can and cannot be run in parallel. You can also split the load of one type of item (eg invoices) into multiple parts with each part loading a separate date range.

- Don't think that the OpenVPMS Loader 'Batch Size' parameter should be large. Experimentation shows that things go faster as it gets smaller: eg 500~112 minutes, 200~107 minutes, 50~96 minutes.
- If at all possible run kettle and MySQL on the same machine. For production you will want MySQL (and Tomcat) running on a dedicated server, but for conversion its better to run all on one system. [Currently I am running two invoice loads in parallel and this is resulting in over 3.3MB/sec of network I/O between Kettle and MySQL.]
The following points all apply to the 'Modified Java Script Value' transform step
Var's not required You only need to use "var" to define a variable if you need it in the next step. If its just an internal work variable, then don't use var.
Always turn off compatibility mode Always disable the compatibility mode. Compatibility should only be set if you have transforms from the earlier versions of Kettle.
Replace may need escape If you use the replace function, be aware that the second argument (string to look for) is in fact a regular expression, and thus that any regex meta characters will need escaping. Futhermore, since in javascript \ needs escaping, you need to double the backslash. Hence, to replace periods (.) by spaces you need replace(str,"\\."," ") and to replace backslashes themselves you need to quadruple them, ie replace(str,"\\\\","x") will replace \ by x. However, since the 'look for' string is a regex expression, you can use replace() to replace multiple characters at the same time.
Hence replace(str,"[\\-\\* ]","x") will replace every minus (-), asterisk (*), and space character by 'x'.
Regex is peculiar If you want to use the str2RegExp function, be aware that the required format of the regex string is not obvious. Firstly you MUST specify string start (^) and string end ($), and you MUST double every backslash. For example the string to look for any-chars9999 9999any-chars OR any-chars99999999any-chars (ie phone numbers) is: "^.*(\\d{4} \\d{4}).*|.*(\\d{8}).*$".
Be careful of plus Javascript uses the + operator to both add numbers and concatenate strings. It also has no specific variable typing facility, and can treat things that you think are numbers as strings. The expression (v1 + v2) may concatenate the two variables. If you need these to be treated as numbers either force the second to be converted to a number by using the Number() function [ie write the expression as (v1 + Number(v2))], or use the fact that the minus operator forces the variable to be treated as a number [ie write the expression as (-(-v1 - v2))].
Another Kettle sample
We run a ranking system for our customers - the top 5 by sales are classified as Platinum, ranks 6 though 25 as Gold, and 26 through 100 as Silver. We have Platinum, Gold and Silver customer alerts (with appropriate colours).
Although we have a report which lists the current customer ranks and what they should be, our staff were not getting the time to do the updates.
To automate the process I wrote some Kettle stuff that implements the following logic:
For each customer in the top 500 by sales volume over the last 180 days, calculate rank as platimum/gold/silver/none then:
If new rank = old rank
If rank not = none
update alert reason to 'Checked on date/time'
Endif
Exit
Else (ie rank changed)
If old rank not = none
Set end date on existing alert to today, and status to COMPLETED
Endif
Create new plat/gold/silver alert
EndifThe attached zip file (renamed to .txt so I can attach it) contains the job and transforms.
The tricks are:
- empty the etl_log file to clean out any old stuff
- create a entry in the etl_log for the user 'sys' - who will be the author of the alerts
- for each top 500 customer create an entry in the etl_log
- both the above steps are necessary so that in the OpenVPMS Loader step we can create the required links to the author and customer.
Even if you don't want to create alerts this code illustrates how to use Kettle to load stuff which references existing data in the system.
Note that I considered writing some SQL to do the complete job, but decided that it was beyond my competance.
Using Kettle to load a product file
I happened to get involved in helping someone load product data from their supplier. (Their initials are CK and hence the file and transform names.)
You will probably have realised that loading OpenVPMS product data is not just a simple matter of loading up a flat file. To get things set up correctly not only do we need to link products to their supplier, but we need to set the Product Type (because a lot of the reporting in OPV has selection via product type, and because the product type also defines the invoice order and (optionally) discounts.
You may have also understood that OPV divides products into medications, merchandise, and services, and that our product loader has to cope with this.
Why Kettle? There is also the dataload tool, and its quite possible to use dataload to load product data. However, if you are starting from a data file provided by the product vendor, you need to process this in the xml format required by dataload. You almost need Kettle to do this processing, so you may as well use Kettle to do the load the data - it certainly gives us flexibility and powerful processing facilities.
If you look inside the attached zip (it has been renamed to ck.zip.txt so that I could attach it) you will find 5 kettle transforms and the kettle job that includes them (so you can run the job rather than the five transforms). There is also an extra transform (see below) than can be used to update prices at a later time. [Note however, that with the advent of the product export/import in OpenVPMS 1.7 this is not really useful.]
Also in the zip are two csv files. CK-supplier contains the single supplier, CK-products contains the products. Note that this is a severely truncated and editied product set. The orginal one contained some 7500 items and has been truncated to protect the supplier's commercial information.
The csv file was generated by loading the supplied text file into Excel and then manipulating it, adding the extra columns, and saving it as a CSV file. So if you want to use these transforms to load your own supplier's data, then you need to process this to match the format of this product file (or modify the transforms).
I also added extra columns as follows:
ProdClass - a single letter to indicate the type of product G=goods=merchandise; M=medication, S=service. If you add your own supplier's data, you can start by tagging everything as G, but you will need to go through and mark the things that should be medication as M. [Recall that medications have a DrugSchedule and a dispensing labels and instructions.] You can also add service items like Consults.
SupplierNo - this is set to 1 for every item. If you include products from another supplier, put 2 here and the add the corresponding line to CK-supplier
Markup - this is the markup index - see the code in the Process step of the CK Products transform, and adjust as you need.
Species - put the species here for items that are species specific. Instructions in the Process step of the CK Products transform. You can leave this column all blank if you want.
FixedPrice - this column is here if you want to add service products, or if you want to put a 'flag-fall' price on some goods or medications. [eg putting a fixed price of $10 on a can of dog food with a unit price of $3 means that 10 cans cost $10+10x$3 = $40.] No problem if you leave blank.
UOM - unit of measure for the item. If you have previously set up the 'Units of Measure' lookup, then you can use the appropriate codes here. No problem if you leave blank.
DrugSched - for the scheduled drugs, put their schedule here (ie S4, S8 etc). Note that although everything has a schedule (ie dog food is S1 - non-dangerous), only medications have a slot for the schedule. This means that if there is some item which you think of as merchandise, but it has a schedule that you need to record, then you Must make the item a medication.
ProdType - the Product Type for the item. What is set here needs to match the Name field in the CK_productTypes.csv file.
The transforms are as follows:
- CK Supplier loads the supplier(s) from the CK_supplier.csv file.
- CK Load Product Type loads the product types from the CK_productType.csc file.
- CK Products loads the products and their prices.
- CK Product Supplier links products to suppliers and adds in the supplier specific information.
- CK Set Product Type sets the product type for each product.
There is also a CK New Prices transform. This uses the same product input file (for simplicity sake) but just updates the prices. [Remember that in OPV a price update does NOT replace the previous prices – it just add the newer ones with the new date. Hence these supersede the old one, but you can see what the old prices were. This happens because the prices are ‘collections’. If you updated a simple field (like Name) then the new data will replace the old.]
Problems:
a) I have not set all the available datafields
b) you will see that I set both the product Name and Printed Name to the name from the Description field in the data file. OPV has done its 'properCase' processing of the Name field, but the standard archetype does not set properCase for the Printed Name field. If you want the name on invoices etc to come out the same as the proper cased name, delete line 2 of the mappings in each of the OPV Loader steps so that Printed Name does not get set (and will default to what is in the Name field).
c) you will have to adjust the folder names set in the xxx.csv steps. You will find that they are all set to " C:\Users\Tim\Documents\HKG Operations\OpenVPMS\Kettle\"
d) naming convention: all variables generated by the Process step are prefixed by 'o'. Hence fields like DrugSched come from the input file and have not been altered.
Using the Openvpms Docloader
Openvpms has a number of methods to enter data or information into your Openvpms MySQL instance. To convert large data sets the OPENVPMS Kettle Plugin for Pentaho Data Intergration version 3.2 should be used, however it is possible to use the dataloader and also the document loaders to enter some data. The dataloader parses a properly structured XML file and loads it into the database, creating the correct linkages as it does so.
The DocumentLoader loads patient or customer documents or attachments into the Database. This article will summarize the available options when using the document loader. Further details explaining how to implement an automatic loader that can load lab results is details here.
http://www.openvpms.org/documentation/automatic-document-importing-openvpms
This will cover the arguments we can use with the docloader
--byid (-i) or --byname (-n) You must use one of these options otherwise the docloader fails.
1.--byid (-i) Using this options looks for an investigation ID to attach the file to. If you specify byid you can also specify
--source (-s) the source directory to load from (default ./)
--dest (-d) the destination to archine processed documents
--regexp a java regexp statement to allow correct parsing of the document name to extract the ID
Default Value = [^\\d]*(\\d+).*
--overwrite (short flag -o ) if used allows you to overwrite existing documents rather than add a new one.
--recurse (short flag -r) if set that will scan the source recursively
--type(-t) I believe you can specify the archetype shortname you are targetting. If not set it will default to Patient Investigations. The archetype short name. May contain wildcards. ie act.*Document*
--context (-c) Default ./applicationContext.xml Please rememeber the .bat or .sh usually sets this to ../conf/applicationContext.xml. So usually you should not set it.
--verbose (-v) Verbose Logging..Logs verbose message to the log or console.
--failonerror (-e) fails on any error. Used for testing purposes usually.
2. --byname (-n) Using this option Load files by matching their names with document acts"
You can only set source, destination, recursive and type when this option is used. Overwrite, and regexp are ignored.
iReports - tips and tricks
NOTE that this is a first draft and may contain errors - if you see any, please comment.
The following may help when you start trying to edit or create reports for OpenVPMS.
Version: although iReports is now up to version 5, for the current version of OpenVPMS (1.6) you need to use iReports 3.7.6.
Manual: you may find that http://jasperreports.sourceforge.net/JasperReports-Ultimate-Guide-3.pdf is useful.
Concepts: OpenVPMS uses two types of 'reports' - those that you run as Reports and which use SQL to extract data from the database, and those that are invoked by various document Print requests - and for these the OpenVPMS code provides the data to the report. For the SQL ones you can use the Preview function with iReports to test your report. For the others, you cannot (unless you are clever and dummy up the required data) so testing is a matter of uploading your new/modified report into the appropriate OpenVPMS report template, and then printing an invoice (or whatever).
Data Source: in order to use the preview function, you have to tell iReports what the data source is. When you start iReports, the initial display (after you dismiss the 'new version available' message box) looks like the following:
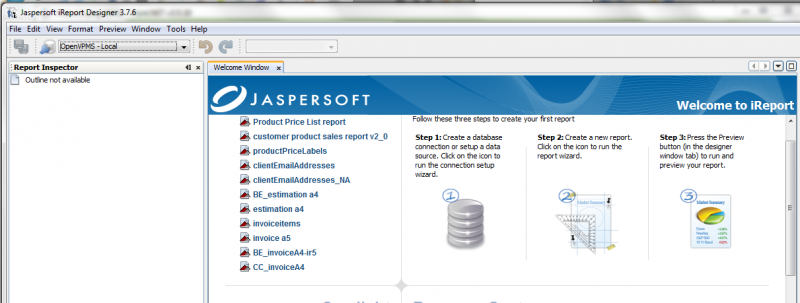
As it says, step 1 is to create the database connection. You need to create a "Database JDBC Connection". You can see in the top left, I have previously created what I called "OpenVPMS - Local". Clicking the 'Report Datasources' button to the left of this shows the available data sources. Below is what I have with the 'OpenVPMS - Local' one (my default) expanded.

If you don't set up the datasource, then by default you will be using iReports 'empty datasource' and your report preview will show nothing.
---to be continued---