OpenVPMS Loader plugin for Pentaho Kettle
This documentation was generated as a result of using OpenVPMS 1.5 and Kettle 3.2
The OpenVPMS Loader Kettle plugin allows mass data to be loaded into the OpenVPMS database.
Since OpenVPMS uses an entity-relationship architecture, rather that the traditional relational database design, one needs a tool that understands the archetypes used by the system. Also, because one does not have the table record keys present in a relational database, there is the potentional problem that having say loaded customer Fred into the system, one cannot at a later time, load in Fred's pets - because Fred's identity number is not known (because it was generated internally by the loader). The Loader plugin provides for this by allowing you to specify an ID field that can be used at a later time to refer to the record previously loaded. Thus Fred's customer record can be loaded with say ID 'C004236' (with 004236 being his client number in some other database), and this ID can be used later when loading Fred's pets. This 'external-key to internal-id' data is recorded in the etl_log file in the database.
The Loader also automatically generates lookup data. Say that the customer archetype defines a field 'title' where the contents must be present in the title lookup table, then without auto lookup generation, you would have to first check the data set to be loaded to see what values are used for the titles (eg Mr, Ms, Dr, Professor, Mde, Doctor) and then create the title lookup table with these entries. With auto lookup generation, this is not necessary and the Loader will create the necessary entries for you. However, you do have the problem that if the incoming data quality is poor (with titles like Mr, MR, Mr. and M R) then you will end up with all these in the lookup table - and you will have to use the Replace facility to clean things up. Hence pre-cleaning of your data is recommended (and Kettle is a very good tool for doing this).
The Kettle Transform step definition window contains the following: (obvious things like the OK button are omitted)
ID Field Name: the name of the field which you want to use as your 'external-key'. This field can be left empty, but you will not be able to later refer to the records being loaded.
Batch Size: this set the number of records loaded before a commit is done. Increasing the number increases the performance at the cost of losing data if a abort occurs. So setting it to say 99999999 will ensure that only one commit is done at the end of the run, but if anything goes wrong nothing will be loaded because all records added will be rolled back out as a result of the transaction failure.
Actually - although the above is logical, its not true. Benchmarking has shown that 50 to 200 is a reasonable optimum for performance.
Generate Lookups: The checkbox is left from previous versions - lookup generation is now always enabled. See OVPMS-1240.
Skip Processed: This checkbox tells the loader what to do about pre-existing records with the same 'external-key'. ie if you have loaded Fred's record in a previous run, what happens when you try to load it again.
If checked, a row that has been previously processed successfully will be skipped.
If not checked, all rows will be reprocessed. Care needs to be taken as this can result in duplicate objects being created.
The following can be set for each field:
Field Name: the name of the field in the step's input record
Map To: The entry here identifies the field to be loaded.
For simple fields its the archetype name and field name, for example <party.customerperson>firstName.
For collections it will have a format like <party.customerperson>contacts[0]<contact.location>address where the index [0] defines this as the first contact.
For cases where you wish to refer to a specific identifier it will have a format like $CLID<party.customerperson>contacts[1]<contact.phoneNumber>telephoneNumber - here CLID is the name of the input field that contains the 'external key' of the customer record loaded earlier for which you wish to set the 2nd contact to be the specified phone number.
Note that the indexes are not absolute indexes - ie its not as though the collection has a set of numbered slots. The indexes serve only to separate the entries for the loader. Hence if we use the second form above (where we are specifying a contact for the customer referenced by $CLID) then the loader will just add this contact to to the customer - and if the customer had 6 contacts already, this will be the 7th, not the second as the [1] appears to indicate. Put another way, the ONLY time you need to use other than [0] as the index is when you happen to be loading multiple members of the collection in the one loader step such as in the example below.

Exclude null: This controls what happens when the incoming field has a null value.
If this is set to N, then a null input will be set on the output field, replacing any default value.
If this is set to Y, then a null input won't be set on the output field, and the default value will be set. If there is no default defined for the field, it will be set to null.
Hence this setting determines whether or not the default value is set for fields whose incoming value is null.
Note that in the supplier example above, the Y's set for the contacts mean that if a field (eg oFax) is null then no fax contact will be created. This means that one does not have to worry about having separate loader steps to cater for cases where some of the data is missing. You just code for thr full data set as above, and rely on Exclude null=Y to omit the fields for which you have no data.
For these cases one uses code like the following in a preceding Javascript step:
var oFax = ""; // init fax number to empty/null
if (SupplierFax != undefined) { //if fax set in data record
oFax = SupplierFax; //set it
}
Value: If you leave this blank, then the data from the incoming field is put into the 'map to' field. However, you can enter expressions here. These will normally operate on the incoming field data in some way as to produce a different value that is put into the 'map to' field. The incoming field data is referred to using '$value'. There are two common formats used here when we are processing fields that have lookup constraints:
a) the <archetype>$value form of the mapping is used when the value refers to an object identifier (see examples below), and implies that the item being referred to must have been previously loaded by the loader.
b) the <archetype>nodename=$value form is used when the value refers to something to be looked up. NOTE that at the current time (1.5.1) the lookup will not be successful if the value you are trying to match contains spaces. See OVPMS-1258
Exclude default objects: As of OpenVPMS 1.5, the "Exclude default objects" column is ignored - you can set it to Y or N. See OVPMS-1239 for details.
Value Examples:
Mapping using nodename= (here we are loading a customer and as part of this setting the account type)
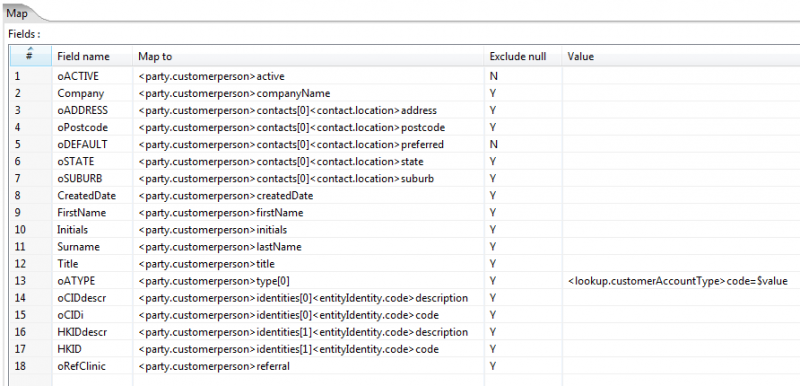
Mapping using values: (here we are connecting previously loaded customers to previously loaded patients)

Error messages:
The Loader plugin is not very good at error checking. a) Kettle's 'Verify this Transformation' checker will not always reveal errors in your entries; b) when an error occurs during the run, the error message is likely to contain little useful data. However, you may find the following helpful.
Message: "Row doesnt contain value: {0}" errors on every row
Meaning: "You twit, you have specified a field name here that is not one of the input fields - check your spelling and capitalisation - also use Get Fields to grab the names of the incoming fields".
Message: "Unexpected error null:" as follows (where 'OpenVPMS Loader.0' is the step name:
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : Unexpected error: null
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : java.lang.NullPointerException
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.load.RowMapper.mapValue(RowMapper.java:192)
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.load.RowMapper.map(RowMapper.java:161)
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.load.Loader.load(Loader.java:115)
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.kettle.LoaderAdapter.load(LoaderAdapter.java:110)
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.kettle.LoaderPlugin.processRow(LoaderPlugin.java:118)
OpenVPMS Loader.0 - ERROR (version 3.2.0-GA...) : at org.openvpms.etl.kettle.LoaderPlugin.run(LoaderPlugin.java:187)
Meaning: you have mis-spelled one of the Map To entries
Message: "Failed to retrieve object" as follows (where nnn is the row id and XXX is the value you are tyring to lookup)
OpenVPMS Loader.0 - Failed to process row nnn: Failed to retrieve object: <lookup.customerAccountType>XXX
Meaning: either you have used the 'object identifier' form rather than the 'code' form (see Value: above) or the object you are referencing really does not exist. See also etl_log below.
Boolean fields
Kettle understands boolean fields. OpenVPMS has boolean fields. However, fields being processed by the Loader should not be in boolean format but rather integer or numeric/precision 0. If you try to load a field like <party.customerperson>active with field typed as boolean, then it will always be set to False. You have to use a Select Fields (or other) step to change the meta data to Integer. Then the field will get loaded correctly. 1 = true, 0 false.
Tricks of the trade
dataload integration If you load data with the dataload utility, then although it uses ID's to link the data being loaded, these IDs are not added to the etl_log file and thus cannot be used by the Kettle loader. However, there is no reason why you cannot inject records into the etl_log file to allow you to link to the records that you loaded using dataload. The attached etl_users.ktr illustrates this. It grabs the user information loaded earlier by dataload and creates the necessary etl_log entries so that when using Kettle to load say visit data, it is easy to reference the associated users and clinicians.
separate steps for linking Because of OPV's entity-relationship structure, is it very common to need to link things together. One of the most basic is the need to link patients to customers. While you might think - load the customers first, then as I load each patient, I will link it to the appropriate customer. This doesn't work - as you attempt to create the link between the customer and patient, although the customer connection will appear to work, the patient end will not. What you need to do is use one transform to load the customers, then one to load the patients and finally a third to build the links between them. Below is an example of the mapping in the Loader transform step used to do this. Note that the ID Field Name for this step is oCRN. oCRN can contain anything that is different on each row - I used the row number of the record from the RxWorks Patient-Owner file I was loading. oCID is the ID of the customer loaded earlier and oPID the patient ID.

SQL editing Kettle uses SQL to pull data from the database you are converting. However, it has very very rudimentary facilities to let you develop the required SQL queries. In my case (converting from RxWork's Access database), I found it far easier to build the query in Access, then display the SQL equivalent and then copy and paste it into the Kettle Table Input step. Because of the join limitations of Access, in some cases you will have to build a prior query in Access (so that the SQL you use ends up using both the RxWorks tables and the prior query you created).
Debug info I found it very useful to have a Text File Output step at the end of the transform which dumped every field from every record/row into a CSV file. When there were errors, this enabled me to look both at the rows in which there were errors, but also at the data in the rows which did not cause an error.
Abort step I also found it useful to have an Abort step as the very last step. During development, you can limit the number of rows processed. When all is working, you just disable the link to the Abort step and all data will be processed. (And because of the 'Skipped Processed Records=Y' setting, the 50 rows at the beginning that loaded with no error will be skipped automatically.)
etl_log An understanding of the etl_log file structure is useful. [More correctly its a table - 'file' betrays my age.] If you use the MySQL Workbench or equivalent you will find that it has three fields of interest (as well as others):
row_id - this contains the value from the field set as 'ID Field Name'
archetype - this contains the archetype being loaded (eg entityRelationship.patientOwner in the example above)
loader - contains the name of the Loader step. This is useful in figuring out which transform/step resulted in this record (sorry 'row').
Hence a useful query is something like 'select * from etl_log where archetype="entity.investigationType" order by row_id;'
Note that since the lookups are done on the basis of archetype/row_id there absolutely no problem in using the same ID's for two different archetypes. There is a major problem if you use the same ID more than once for the one archetype. [There will not be any problem as the data is loaded, but if you ever need to reference it, you will get 'refers to multiple ...' errors.]
Product varieties OPV divides products into three varieties, medication, merchandise, and services, each with its own archetype. This means that when loading product data, you need to use three different OPV Loader steps, and steer the processing to use the appropriate one (see below). Hence your processing needs to have some method of deciding on the variety of the product. Bear in mind that only medications can have labels, hence if there is some product that you think of as merchandise, you will need to class this as medication if you need to be able to print a label for it. (The example I found was a shampoo, which required a 'for external use only' label.)
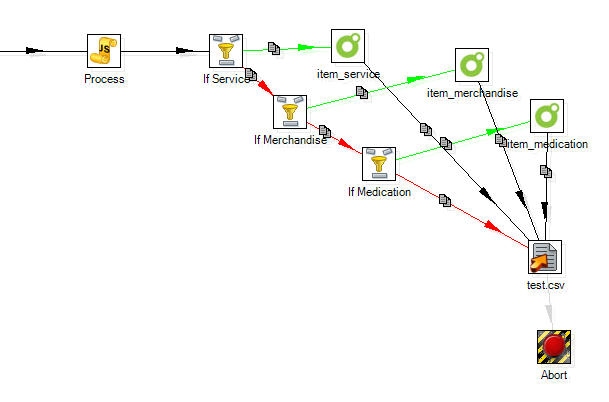
Need to Split Processing In some cases where you need to process medications, merchandise, and services it may be necessary to split the transform. That is, although you might think that its possible to use a transform with the above design with three separate loader steps, if you do this, you will get problems with Kettle running out of heap space. The solution is to clone the transform into 3, with each just processing one product variety. The problem seems to occur if the loader needs to update multiple records. For example the mapping given below (in which I am setting the product type for products loaded by an earlier transform) caused heap overflows if I used the above '3 loader steps in one transform' design, but ran happily when I split it into three transforms, one for each of service, merchandise and medications.

Reading the archetype As you are developing transforms you will want to refer to the archetypes. Don't using the Export facility on the Administration|Archetypes screen - it generates a very complete but overly complex adl file. If you do want to look at a file, grab a copy of the adl file from the <OPV-HOME>\update\archetypes\org\openvpms\archetype folders. Alternatively, look at the archetype via the Administration|Archetypes screen. Note however, that if you use View, you will not be able to see the full archetype. Specifically, if the archetype has a node that links to multiple archetypes (eg participation.product's entity node), then if you use View, you will only be shown one. To see all four you need to Edit the archetype.
- Printer-friendly version
- Login or register to post comments




Comments